What is ‘Thematic Search’?
What do we even mean by thematic search? How does it differ from semantic search? How does it work mathematically?
On this page, we will answer these questions through a mix of theory and example. First, our starting assumptions. Our baseline assumption is that we have a corpus of documents, and a hierarchical topic model for this corpus. In particular, a “topic” here means a set (or fuzzy set) of documents, and “hierarchical” means that topics come with some measure of coarseness or specificity, such as depth in a topic tree.
Conceptually, thematic search refers to two dual search operations:
Given a topic, which documents belong to that topic?
Given a set of documents, what is their theme?
By “theme” we mean the most specific topic containing the documents. The first operation searchs the set of documents and conversely the second operation searchs the set of topics.
As a running example, we will use the 20 Newsgroups dataset. Samples in this dataset are Usenet forum posts, and they are labeled with a ‘newsgroup’ attribute that says which topic they were posted to. Let’s load up a TopicDatabase of 20 Newsgroups. The page Searching 20-Newsgroups shows how we prepared the data for thematic search.
[26]:
import thematic_search as ts
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("sentence-transformers/all-mpnet-base-v2")
topicdb = ts.TopicDatabase.from_file('docs/source/20ng-topicdb.tm.zip')
topicdb.embedding_model = model
Warning: You are sending unauthenticated requests to the HF Hub. Please set a HF_TOKEN to enable higher rate limits and faster downloads.
MPNetModel LOAD REPORT from: sentence-transformers/all-mpnet-base-v2
Key | Status | |
------------------------+------------+--+-
embeddings.position_ids | UNEXPECTED | |
Notes:
- UNEXPECTED :can be ignored when loading from different task/architecture; not ok if you expect identical arch.
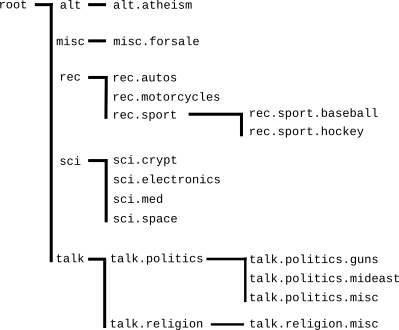
Here is a sub-tree of the topic tree of the dataset:
Searching documents by topic
The more straight-forward operation is searching the set of documents by topic. For example, searching for documents about science should return us documents from the four sub-newsgroups sci.crypt, sci.electronics, sci.med and sci.space.
[ ]:
topicdb.q.topic_name("sci").samples().metadata()
| post | newsgroup | |
|---|---|---|
| 5 | \n\nBack in high school I worked as a lab assi... | sci.electronics |
| 11 | >say they have a "history of untrustworthy be... | sci.crypt |
| 13 | How about Kirlian imaging ? I believe the FAQ... | sci.med |
| 16 | Many thanks to those who replied to my appeal ... | sci.electronics |
| 17 | .........\nI, some years ago, almost became a ... | sci.electronics |
| ... | ... | ... |
| 18143 | \nYou'd have to purify the river water first. ... | sci.med |
| 18158 | \nProbably keep quiet and take it, lest they g... | sci.crypt |
| 18159 | \nThey've been out of busines for years.\n\n\n... | sci.electronics |
| 18165 | DN> From: nyeda@cnsvax.uwec.edu (David Nye)\nD... | sci.med |
| 18166 | \nNot in isolated ground recepticles (usually ... | sci.electronics |
3804 rows × 2 columns
Although it is straight-forward, it is surprisingly hard to replicate with keyword or semantic search. For example, searching by the keyword “science” gives:
[ ]:
topicdb.q.samples_where("post.str.contains('science')").metadata()
| post | newsgroup | |
|---|---|---|
| 275 | \nReading this definition, I wonder: when shou... | sci.med |
| 388 | #In article <1r3tqo$ook@horus.ap.mchp.sni.de>\... | alt.atheism |
| 389 | -*-----\n\nI think the question is: What is ex... | sci.med |
| 435 | \n\nPoint 1:\n\nI'm beginning to see that *par... | sci.med |
| 479 | I am posting this for a friend without interne... | sci.space |
| ... | ... | ... |
| 17671 | \n\tFirst of all, I resent your assumption tha... | soc.religion.christian |
| 17811 | Brian Yamauchi asks: [Regarding orbital billbo... | sci.space |
| 17815 | \n\n\nSorry, but yes he does, by your own desc... | talk.religion.misc |
| 17823 | Reposted by request ... these images are great... | comp.graphics |
| 18013 | \n\nOops, sorry, my words, not the words of th... | alt.atheism |
251 rows × 2 columns
We see that we’ve only found 251 posts, compared to 3804 from the thematic search, and the topics of these posts are much more spread out.
On the other hand, maybe we can do better with a semantic search? Well, semantic search immediately raises the issue that we must choose the number of nearest-neighbours to search for. We know from our thematic search that there are 3804 documents in the science topic, so what if we set \(k=3804\)?
[ ]:
results = topicdb.q.neighbours("science", k=3804).metadata()
print('unique newsgroups:', set(results.newsgroup.values))
results
unique newsgroups: {'talk.politics.mideast', 'soc.religion.christian', 'sci.crypt', 'rec.motorcycles', 'rec.autos', 'talk.politics.misc', 'alt.atheism', 'misc.forsale', 'rec.sport.hockey', 'sci.med', 'sci.space', 'comp.graphics', 'rec.sport.baseball', 'talk.politics.guns', 'comp.sys.mac.hardware', 'sci.electronics', 'talk.religion.misc', 'comp.os.ms-windows.misc', 'comp.sys.ibm.pc.hardware', 'comp.windows.x'}
| post | newsgroup | |
|---|---|---|
| 1835 | \nScience is the process of modeling the real ... | alt.atheism |
| 3283 | ... | rec.sport.baseball |
| 13984 | \n\t\t\t ^^^^\n\nJust what are these "scient... | soc.religion.christian |
| 10076 | -- \njamiller@kuhub.cc.ukans.edu\nJames Miller | misc.forsale |
| 15310 | \n\t\t\t\t\tart\n | comp.sys.mac.hardware |
| ... | ... | ... |
| 15229 | I believe that the large number of digits... | rec.sport.hockey |
| 16154 | It is NOT a homeopathic remedy. Improvement be... | sci.med |
| 14837 | \nWhere did you hear this? If it is printed i... | comp.windows.x |
| 14 | \n\n\tThere is no notion of heliocentric, or e... | alt.atheism |
| 4313 | For the second straight game, California score... | rec.sport.baseball |
3804 rows × 2 columns
This results in posts from literally every topic in the dataset. It could be however that in fact these posts are about science- for example that first post (index 1835) looks promising, let’s look at the full text:
[43]:
print(results.post.values[0])
Science is the process of modeling the real world based on commonly agreed
interpretations of our observations (perceptions).
Values can also refer to meaning. For example in computer science the
value of 1 is TRUE, and 0 is FALSE. Science is based on commonly agreed
values (interpretation of observations), although science can result in a
reinterpretation of these values.
The values underlaying science are not objective since they have never been
fully agreed, and the change with time. The values of Newtonian physic are
certainly different to those of Quantum Mechanics.
Sure, that seems like it is “about science”. How about that last post (index 4313)?
[44]:
print(results.post.values[-1][0:280], "...")
For the second straight game, California scored a ton of late runs to crush
the Brewhas. It was six runs in the 8th for a 12-5 win Monday and five in
the 8th and six in the 9th for a 12-2 win yesterday. Jamie Navarro pitched
seven strong innings, but Orosco, Austin, Manzanillo an ...
That’s not about science! Of course, in practice we’d probably take a much smaller number of nearest-neighbours, and doing that gives pretty good results:
[ ]:
topicdb.q.neighbours("science", k=20).metadata()
| post | newsgroup | |
|---|---|---|
| 1835 | \nScience is the process of modeling the real ... | alt.atheism |
| 3283 | ... | rec.sport.baseball |
| 13984 | \n\t\t\t ^^^^\n\nJust what are these "scient... | soc.religion.christian |
| 10076 | -- \njamiller@kuhub.cc.ukans.edu\nJames Miller | misc.forsale |
| 15310 | \n\t\t\t\t\tart\n | comp.sys.mac.hardware |
| 1230 | -*----\nI think that part of the problem is th... | sci.med |
| 14489 | Posted by Cathy Smith for L. Neil Smith\n\n ... | talk.politics.guns |
| 9688 | Archive-name: space/mnemonics\nLast-modified: ... | sci.space |
| 2290 | \nCrullerian.\n\n\nCrullerian photography isn'... | sci.med |
| 3449 | \nSays who? Other than a hear-say god.\n\n\nYo... | alt.atheism |
| 8740 | \nNowadays, usually with a computer. No theory... | sci.space |
| 5387 | -- \n ____\n Y_,_|[]| Ernest Stalnaker... | comp.sys.mac.hardware |
| 4625 | [...stuff deleted...]\n\nThank you. I thought... | alt.atheism |
| 389 | -*-----\n\nI think the question is: What is ex... | sci.med |
| 11666 | \nWhether a scientific idea comes while one is... | sci.med |
| 13976 | Brandon Wise\nbwise@nyx.cs.du.edu\n\n\n | comp.os.ms-windows.misc |
| 4637 | \ntry sci.energy | sci.electronics |
| 1136 | In-Reply-To: <20APR199312262902@rigel.tamu.edu... | comp.graphics |
| 4047 | \nRobert McElwaine is the authoritative source... | sci.space |
| 15026 | \n\nFor a brief, but pretty detailed account, ... | sci.med |
However it shows that searching by topic does something new and conceptually different than other search techniques.
Finding the theme of a set of documents
Going in the other direction, we can take a set of documents, and ask for their theme. This is a useful thing to ask in exploratory analysis of data. We want to understand what these documents have in common, and as specifically as possible.
For example, lets take a handful of documents about baseball and hockey and ask for their theme. Refering to the 20 Newsgroups topic-tree at the top of the page, we can see that the most-specific topic that contains rec.sport.baseball and rec.sport.hockey is rec.sport. That is, the theme is sports.
In code:
[ ]:
input_docs = topicdb.q.samples([0,7,8,33,18132]).metadata()
input_docs
| post | newsgroup | |
|---|---|---|
| 0 | \n\nI am sure some bashers of Pens fans are pr... | rec.sport.hockey |
| 7 | \n[stuff deleted]\n\nOk, here's the solution t... | rec.sport.hockey |
| 8 | \n\n\nYeah, it's the second one. And I believ... | rec.sport.hockey |
| 33 | \nBe patient. He has a sore shoulder from cras... | rec.sport.baseball |
| 18132 | Can someone send me ticket ordering informatio... | rec.sport.baseball |
[ ]:
topicdb.q.samples([0,7,8,33,18132]).theme().metadata()
| name | layer | cluster | |
|---|---|---|---|
| uid | |||
| AAQH | rec.sport | 1 | 6 |
Mathematically, one could define the theme of the set of documents to be the least upper bound (in the topic tree) of the set of topics containing at least one of the documents. That is, theme should be equivalent to topics + least upper bound:
[ ]:
topicdb.q.samples([0,7,8,33,18132]).topics().least_upper_bound().metadata()
| name | layer | cluster | |
|---|---|---|---|
| uid | |||
| AAQH | rec.sport | 1 | 6 |
Although this makes mathematical sense, it has one major drawback in practice. Often you will have a set of documents where most of the documents share a common theme, but there are a couple spurrious other documents. These spurrious documents can be on topics in a completely separate branch of the topic tree, meaning that the least upper bound of the set of all topics ends up very far up the tree.
For example, let’s throw in an extra document from rec.autos in there and compare the two queries:
[ ]:
print(topicdb.q.samples([0,7,8,33,18132,18169]).metadata())
print("="*50)
least_upper_bound_result = topicdb.q.samples([0,7,8,33,18132,18169]).topics(
).least_upper_bound().metadata()['name'].values[0]
theme_result = topicdb.q.samples([0,7,8,33,18132,18169]).theme().metadata()['name'].values[0]
print(f"Least Upper Bound of Topics is: {least_upper_bound_result}")
print(f"Theme of the Documents is: {theme_result}")
post newsgroup
0 \n\nI am sure some bashers of Pens fans are pr... rec.sport.hockey
7 \n[stuff deleted]\n\nOk, here's the solution t... rec.sport.hockey
8 \n\n\nYeah, it's the second one. And I believ... rec.sport.hockey
33 \nBe patient. He has a sore shoulder from cras... rec.sport.baseball
18132 Can someone send me ticket ordering informatio... rec.sport.baseball
18169 After a tip from Gary Crum (crum@fcom.cc.utah.... rec.autos
==================================================
Least Upper Bound of Topics is: rec
Theme of the Documents is: rec.sport
The least upper bound of {rec.sport.hockey, rec.sport.baseball, rec.autos} is rec, but the overall theme of the documents is still rec.sport. The difference can be even more pronounced if we do nearest-neighbour search to obtain our input documents:
[ ]:
print(topicdb.q.neighbours("sports", k=15).metadata())
print("="*50)
least_upper_bound_result = topicdb.q.neighbours("sports", k=15).topics(
).least_upper_bound().metadata()['name'].values[0]
theme_result = topicdb.q.neighbours("sports", k=15).theme().metadata()['name'].values[0]
print(f"Least Upper Bound of Topics is: {least_upper_bound_result}")
print(f"Theme of the Documents is: {theme_result}")
post \
6623 BASEBALL.....ALWAYS\nhow he\n\n
12791 Since someone brought up sports radio, howabou...
7945 I found this press release from Trial Lawyers ...
13714 boxscores.\n\nBeware. The original poster loo...
15310 \n\t\t\t\t\tart\n
4950 Can some on e give me some stats on Forsrg in ...
11528 \n\n\nWoops! This is rec.sport.hockey! Not re...
1423 Archive-name: rec-autos/part1\n\n[most recent ...
15420 ------------------------- Original Article ---...
11480 One week to the Robot Olympic games. Fire up ...
5376 \nDancing With Idjits.\n\n\n
15541 I sent a version of this post out a while ago,...
15206 Here's an easy question for someone who knows ...
11932 \nAnd thus, we come to one of the true beautie...
16342 \n\n\n\nI hear ya, brother.\n\n ^^^^^^^...
newsgroup
6623 rec.sport.baseball
12791 rec.sport.baseball
7945 rec.sport.hockey
13714 rec.sport.baseball
15310 comp.sys.mac.hardware
4950 rec.sport.hockey
11528 rec.sport.hockey
1423 rec.autos
15420 rec.sport.baseball
11480 sci.electronics
5376 rec.motorcycles
15541 rec.sport.baseball
15206 rec.sport.baseball
11932 rec.sport.baseball
16342 rec.sport.baseball
==================================================
Least Upper Bound of Topics is: root
Theme of the Documents is: rec.sport
The nearest-neighbour results are sufficient spread across the set of topics that the their least upper bound in the topic tree is the root node!
So how does the theme function get around this? Theme searches for a topic that minimizes an objective function that simultaneously tries to maximize the number of documents included in the topic (weighted by inclusion strength) while minimizing how far up the topic tree the node is. Instead of a “least upper bound”, its more of a “lowish, almost-upper-bound”.
This trade-off makes the thematic search much more robust to imperfectly categorized data, especially when we are working with datasets that have soft cluster strengths.